Stable Diffusion LoRA Fine-Tuning
LoRA tekniği ile Stable Diffusion modelini fine-tune ederek kişiselleştirilmiş görseller üretme
Stable Diffusion LoRA Fine-Tuning
Bu proje, Stable Diffusion v1.5 modelini özel bir veri seti ile fine-tune etmek için LoRA (Low-Rank Adaptation) tekniğini kullanır. Model, köpek görselleri üzerinde eğitilmiş olup, "sks dog" trigger kelimesi ile kişiselleştirilmiş görseller üretebilir.
Hızlı Başlangıç
Eğitilmiş modeli hemen kullanmaya başlayabilirsiniz:
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"stable-diffusion-v1-5/stable-diffusion-v1-5",
torch_dtype=torch.float16
).to("cuda")
pipe.load_lora_weights("erdoganeray/finetune-demo")
image = pipe("a photo of sks dog wearing sunglasses").images[0]
image.save("output.png")Hugging Face Model: erdoganeray/finetune-demo
Özellikler
- Verimli Eğitim: LoRA ile sadece %0.5-1 oranında parametre eğitimi
- Küçük Model Boyutu: ~3MB LoRA adapter (~4GB full model yerine)
- Kolay Kullanım: Jupyter notebook ile adım adım eğitim
- Hugging Face Uyumlu: Model doğrudan Hub'a yüklenebilir
- Detaylı İzleme: Loss grafikleri ve checkpoint mekanizması
- Çeşitli Test Prompt'ları: 20 farklı stil ve senaryo
LoRA Nedir?
LoRA (Low-Rank Adaptation), büyük modelleri verimli bir şekilde fine-tune etmemizi sağlayan bir tekniktir. Tüm model ağırlıklarını güncellemek yerine:
- Orijinal model ağırlıklarını dondurur
- Belirli katmanlara küçük "adapter" matrisleri ekler
- Sadece bu adapter matrislerini eğitir
Avantajları:
- ~%99 daha az eğitilebilir parametre
- Çok daha hızlı eğitim
- Çok küçük model dosyaları (~3MB vs ~4GB)
- Diğer LoRA'larla kolayca birleştirilebilir
Model Mimarisi
Temel Bileşenler
| Bileşen | Model |
|---|---|
| Base Model | Stable Diffusion v1.5 |
| Text Encoder | CLIP ViT-L/14 |
| VAE | AutoencoderKL |
| UNet | 2D Conditional UNet |
LoRA Konfigürasyonu
LoraConfig(
r=32, # Rank (kapasite)
lora_alpha=64, # Scaling factor (rank * 2)
lora_dropout=0.05, # Regularization
target_modules=[ # Attention katmanları
"to_k", "to_q",
"to_v", "to_out.0"
]
)Eğitilebilir Parametreler: ~3.1M / 860M (%0.36)
Eğitim Detayları
Hiperparametreler
| Parametre | Değer | Açıklama |
|---|---|---|
| Epochs | 300 | Toplam eğitim döngüsü |
| Learning Rate | 5e-5 → 5e-6 | Cosine annealing |
| Optimizer | AdamW | Weight decay ile |
| Batch Size | 1 | Her epoch'ta 1 random görsel |
| Gradient Clipping | 1.0 | Stabilite için |
| Image Size | 512×512 | Standart SD boyutu |
| Augmentation | Evet | Flip, ColorJitter |
Veri İşleme
Augmentation Pipeline:
- Random Horizontal Flip (p=0.5)
- Color Jitter (brightness, contrast, saturation: 0.1)
- Normalization (mean=0.5, std=0.5)
Veri Seti: diffusers/dog-example (~5 köpek görseli)
Eğitim Veri Seti Örnekleri
Model, küçük bir köpek görseli veri seti üzerinde eğitildi:


Sonuçlar
Loss Metrikleri
| Metrik | Değer |
|---|---|
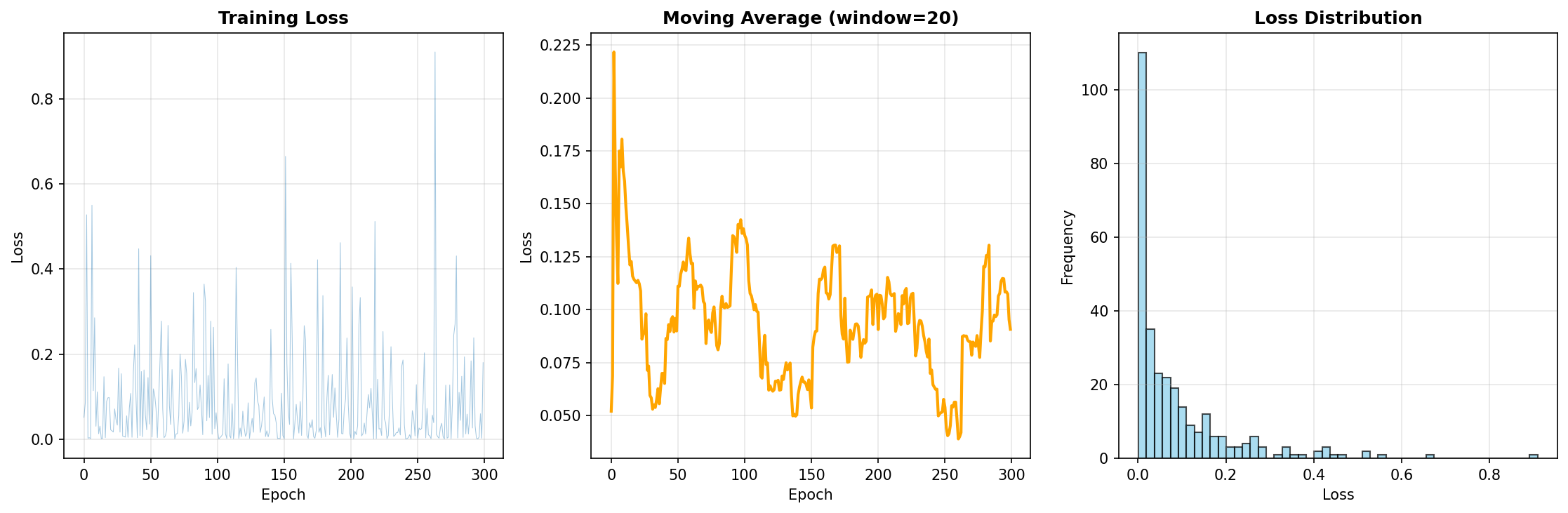
| Final Loss | 0.1804 |
| Average Loss | 0.0876 |
| Min Loss | ~0.05 |
Gözlemler:
- Loss değerleri düzenli bir şekilde azaldı
- Overfitting belirtisi görülmedi
- 300 epoch yeterli convergence sağladı
Benchmark
| Metrik | Değer |
|---|---|
| Eğitim Süresi | ~45 dakika (T4 GPU) |
| Model Boyutu | 3.2 MB (LoRA) |
| Inference Süresi | ~5 saniye/görsel (50 steps) |
| VRAM Kullanımı | ~8 GB (fp16) |
Eğitim Loss Grafiği
Kullanım Örnekleri
Yöntem 1: Hugging Face'den Kullanma (Önerilen)
from diffusers import DiffusionPipeline
import torch
# Pipeline'ı yükle ve LoRA adapter'ı ekle
pipe = DiffusionPipeline.from_pretrained(
"stable-diffusion-v1-5/stable-diffusion-v1-5",
torch_dtype=torch.float16
).to("cuda")
pipe.load_lora_weights("erdoganeray/finetune-demo")
# Görsel üret
image = pipe(
"a photo of sks dog wearing sunglasses",
num_inference_steps=50,
guidance_scale=7.5
).images[0]
image.save("output.png")Yöntem 2: PEFT ile Alternatif Kullanım
from diffusers import StableDiffusionPipeline
from peft import PeftModel
import torch
# Base pipeline yükle
pipe = StableDiffusionPipeline.from_pretrained(
"stable-diffusion-v1-5/stable-diffusion-v1-5",
torch_dtype=torch.float16
).to("cuda")
# LoRA adapter'ı Hugging Face'den yükle
pipe.unet = PeftModel.from_pretrained(
pipe.unet,
"erdoganeray/finetune-demo"
)
# Görsel üret
image = pipe("sks dog in a cyberpunk city, neon lights").images[0]
image.save("output.png")Gelişmiş Parametreler
image = pipe(
prompt="sks dog in a cyberpunk city, neon lights",
negative_prompt="blurry, bad quality",
num_inference_steps=50, # Daha fazla = daha kaliteli
guidance_scale=7.5, # Prompt'a bağlılık
height=512,
width=512,
).images[0]Batch Üretim
prompts = [
"sks dog on a beach",
"sks dog in winter",
"sks dog as superhero"
]
for i, prompt in enumerate(prompts):
image = pipe(prompt).images[0]
image.save(f"output_{i}.png")Üretilen Görsel Örnekleri
Model, çeşitli stil ve senaryolarda başarılı görseller üretebiliyor. Üretilen çıktıların galerisi:

Örnek Çıktılar
 sks dog in a bucket
sks dog in a bucket sks dog in a garden
sks dog in a garden sks dog astronaut
sks dog astronaut sks dog Van Gogh style
sks dog Van Gogh styleFarklı Ortamlar:
- Uzay kıyafeti giyen köpek
- Tropik plajda köpek
- Şömine yanında köpek
- Karda oynayan köpek
Sanat Stilleri:
- Van Gogh tarzı yağlı boya
- Suluboya resim
- Rönesans tarzı
- Pixel art 8-bit
Kostüm ve Aksesuarlar:
- Altın taç takan köpek
- Güneş gözlüğü ve deri ceket
- Süper kahraman kıyafeti
- Büyücü şapkası
Fantastik Senaryolar:
- Cyberpunk karakter
- Sihirli orman
- Ay'da astronot
- Sualtı sahnesi
Linkler
- GitHub Repository: erdoganeray/stable_diffusion_lora_finetuning
- Hugging Face Model: erdoganeray/finetune-demo
- Eğitim Veri Seti: diffusers/dog-example
Lisans
Bu proje MIT Lisansı ile lisanslanmıştır. Stable Diffusion v1.5 modeli CreativeML OpenRAIL-M lisansı altındadır.